class: center, middle, inverse, title-slide .title[ # The measurement of meaning in social media ] .author[ ### David Garcia <br><br> <em>University of Konstanz</em> ] .date[ ### Social Media Data Analysis ] --- layout: true <div class="my-footer"><span>David Garcia - Social Media Data Analysis</span></div> --- # Outline ## 1. The semantic differential ## 2. Word embeddings ## 3. Language models for social media ## 4. Emotion identification in social media text --- ### Psycholinguistics: How individuals use and adopt language .center[] **De Saussure's model of language** - Language as association between signified (meaning) and signifier (word) - Associations are normative and agreed through learning - Human communication is composed of two steps: 1. **Encoding:** Transforming thoughts into words 2. **Decoding:** Translating words into thoughts --- # Connotative vs denotative meanings   - **Denotative meaning:** Definition of a word in reference to other meanings - **Connotative meaning:** Emotional association of the use of a word - Sentiment analysis aims to measure the **connotative meaning** of texts --- # The Semantic Differential **Charles Osgood's Semantic Differential:** Rating scales to measure the connotative meanings of words, objects, events (or symbols in general) Osgood's method to find the dimensions of meaning: 1. Select a set of objects/words/symbols to measure their meaning 2. Design a large set of questions or scales about the symbols 3. Ask some people to rate the symbols according to the scales 4. Apply dimensionality reduction/factor analysis 5. Interpret factors into dimensions of meaning *The measurement of meaning. C. Osgood, G. Suci, P. Tannenbaum, 1957* --- # Word ratings for the semantic differential .center[] - Stimulus: One word, in this case *polite* - Response: Ratings of each participant for the word in relation to adjectives --- ## Semantic differential example: fonts .center[] --- .center[] --- ## Dimensionality reduction: Factor analysis .center[] - The N-dimensional cloud of (average) ratings of words is processed with factor analysis - Each factor is a vector in the N-dimensional space. Factors are orthogonal - Factors are ordered such that the first one has the most variance - The result is a smaller set of dimensions that represents the ratings of words to certain extent (explained variance) --- # Three dimensions of meaning .pull-left[.center[]] .pull-right[ The dimensions of the Semantic Differential (EPA): - **Evaluation:** good, desirable -- bad, undesirable - **Potency:** strong, powerful -- weak, powerless - **Activation:** active, fast -- passive, slow] - Evaluation has the most variance, i.e is the most explanatory - Potency and Activation have similar explanatory level below Evaluation --- # Word embeddings ## 1. The semantic differential ## *2. Word embeddings* ## 3. Language models for social media ## 4. Emotion identification in social media text --- layout: true <div class="my-footer"><span>Speech and Language Processing. Daniel Jurafsky & James H. Martin. (2023)</span></div> --- # Documents as vectors  - Remember bag of words: term frequency counts ignoring order - Example just for four words in four books as documents - Here, each book is represented by a four-dimensional vector (vertical here) [Speech and Language Processing. Daniel Jurafsky & James H. Martin. (2023)](https://web.stanford.edu/~jurafsky/slp3/6.pdf) --- # Documents as vectors .center[] --- # Measuring similarity The similarity between the content of two documents can be measured with the cosine similarity of their vector representations: `$$sim(u,v) = cos(\theta) = \frac{u\cdot v}{\|u\| \|v\|} = \frac{\sum^n_{i=1}{u_iv_i}}{ \sqrt{\sum^n_{i=1} u_i^2} \sqrt{\sum^n_{i=1} v_i^2}}$$` `$$sim(d_1, d_2) = \frac{1*0 + 114*80 + 36 * 58 + 20 * 15}{\sqrt{1+114^2+36^2+20^2} \sqrt{80^2+58^2+15^2}} \sim 0.95$$` - `\(d_1\)`: As You Like It - `\(d_2\)`: Twelfth Night --- # Cosine similarity example .center[] --- # Words as vectors .center[] - Instead of looking at document vectors, we can use word vectors - These vectors can approximate the meaning similarity between words - `\(sim(fool, wit) \sim 0.93\)` - `\(sim(fool, battle) \sim 0.09\)` - *fool* is not a synonym of *wit*, but its meaning is closer to *wit* than to *battle* --- ## Language sparsness and the curse of dimensionality .pull-left[ - Human languages have lots of different words - Heap's law: Vocabulary size grows (sublinearly) with corpus size - More documents, more words - Word and document matrices become too sparse - Hard to do statistics or train models when the vast majority of variables are zeroes - Larger corpora might not exist! ] .pull-right[ Number of distinct words (vocabulary size) versus corpus size (in tokens)] --- # Latent Semantic Analysis - Aim of LSA: making word and document vectors denser (less dimensions) - Idea: Singular Value Decomposition of word-document matrix - Problem: Very computationally intensive as soon as matrix gets large .center[] https://www.geeksforgeeks.org/latent-semantic-analysis/ --- # Distributed representations **The distributional hypothesis: Words that occur in similar contexts tend to have similar meanings** -- "You Shall Know a Word by the Company It Keeps" .center[] --- ## Self-supervision: Continuous Bag Of Words - Idea: training a model to predict words from their context: .center[the quick brown fox ... over the lazy dog] - Self-supervision: train it with corpus, without annotations - Represent each word `\(w\)` with a vector `\(\mu_{w}\)` in a lower-dimensional space compared to the word-document matrix (50-700 dimensions) - Fit the values of `\(\mu_w\)` with self-supervision such that: $$ argmax_{\mu_w} = \frac{exp(\mu_w \cdot \vec{v})}{\sum_j exp(\mu_j \cdot \vec{v})} $$ where `\(\vec{v}\)` is the mean vector for the words in the context and `\(j\)` iterates over the words in the language --- layout: true <div class="my-footer"><span>David Garcia - Social Media Data Analysis</span></div> --- .pull-left[ # ML Warning In this lecture we focus on applications, not development We will gloss over details, see references and related courses to learn more ] .pull-right[] --- # Word embeddings - After fitting, the resulting `\(\mu_w\)` are called **word embeddings** - Also called word representations: `\(R(w)\)` - Operating on embeddings space allow us to extract dimensions of meaning or compute analogies: .center[] --- # Word embeddings in practice You don't need to fit your own word embeddings model, several alternatives exist that are already trained: - word2vec [(Mikolov, Chen, Corrado, and Dean, 2013)](https://arxiv.org/abs/1301.3781) - Developed by Google - trained against Wikipedia - Based on CBOW and Skipgrams (predict context from word) - GloVe [(Pennington, Socher, Manning, 2014)](https://aclanthology.org/D14-1162/) - "global" embeddings using a larger definition of context - Developed by Stanford NLP group, similar to word2vec - fastText [(Bojanowski, Grave, Joulin, Mikolov, 2017)](https://arxiv.org/abs/1607.04606) - Developed by Facebook - trained against Wikipedia in many languages - Uses character-level tokenization: it can embed new words based on how they are written (e.g. composite words from the embeddings of lemmas) --- # Distributed Dictionary Representation .center[] [Dictionaries and distributions: Combining expert knowledge and large scale textual data content analysis. J. Garten, J. Hoover, K. Johnson, R. Boghrati, C. Iskiwitch & M. Dehghani. Behavior Research Methods (2018)](https://link.springer.com/article/10.3758/s13428-017-0875-9) --- # Distributed Dictionary Representation .center[] - Two tests: predicting if movie reviews are positive or negative and identifying moral foundations in tweets - DDR outperforms word counting and performs best when applied on a smaller dictionary - larger dictionaries is not better in this case --- # Evidence and belief in political text .center[] --- # DDR examples .center[] --- # Evidence and belief and misinformation .center[] [From alternative conceptions of honesty to alternative facts in communications by US politicians. Lasser et al. Nature Human Behavior (2023)](https://www.nature.com/articles/s41562-023-01691-w) --- # Language models for social media ## 1. The semantic differential ## 2. Word embeddings ## *3. Language models for social media* ## 4. Emotion identification in social media text --- # The Attention layer .center[] Speech and Language Processing. Daniel Jurafsky & James H. Martin (2023) --- # The Transformer Block .center[] Speech and Language Processing. Daniel Jurafsky & James H. Martin (2023) --- ### BERT: Bidirectional Encoder Representations from Transformers .center[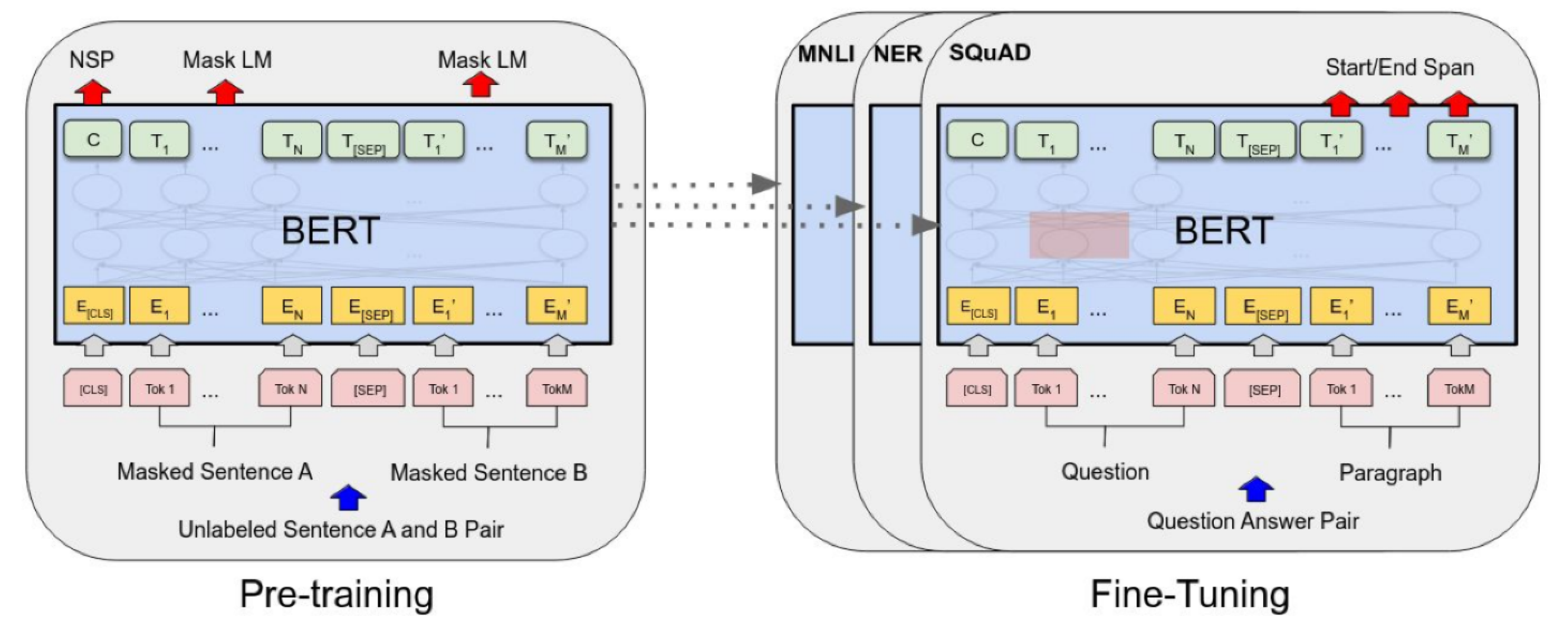] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Devlin et al (2018) --- # More from BERT - Transformers are neural networks which use attention mechanism - A "large" language model (LM) - Base with 12 Transformer layers (110 million parameters) - Large with 24 Transformer layers (340 million parameters) - Trained on large collection of text: Wikipedia and BookCorpus - With several specialized hardware GPUs/TPUs - Examples of LMs based on Transformers: RoBERTa, XLNET, ELECTRA - Now: Examples of use of Transformers in social media analysis --- # Perspective API: Toxicity .center[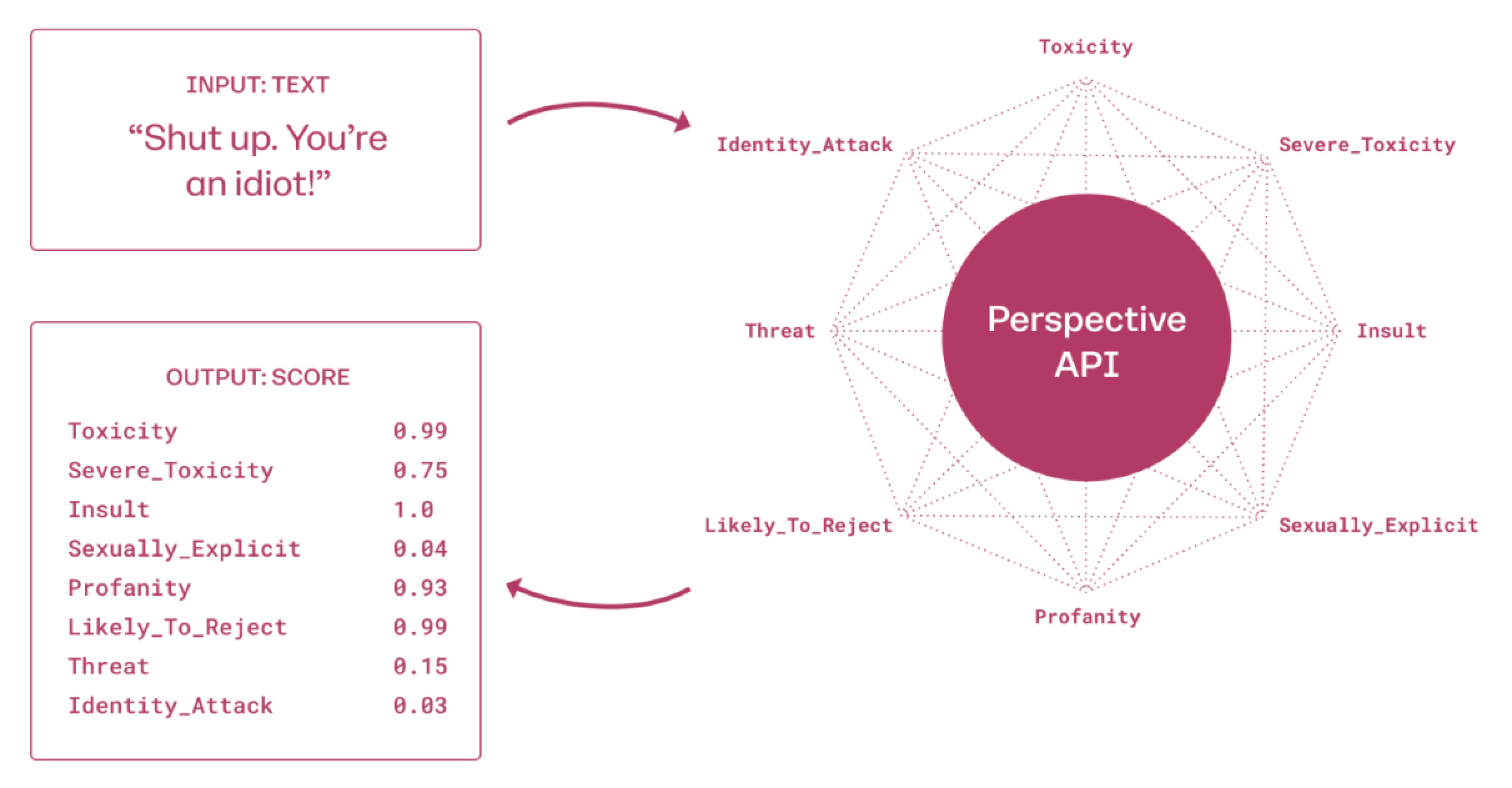] --- # About Perspective Toxicity models *We start by training multilingual BERT-based models on data from online forums. We then distill these models into single-language Convolutional Neural Networks (CNNs) for each language we support. Distillation ensures we can serve the models and produce scores within a reasonable amount of time.* .center[] *Perspective’s main attribute is TOXICITY, defined as “a rude, disrespectful, or unreasonable comment that is likely to make you leave a discussion”.* --- ## HuggingFace: Open source toxicity models .center[] --- # Transformers for sentiment on tweets .center[] --- # Example: Suicide content detection .center[] [Detecting potentially harmful and protective suicide-related content on Twitter: A machine learning approach. Metzler et al. JMIR (2022)](https://www.jmir.org/2022/8/e34705) --- # BERT results .center[] --- # Application to suicide statistics .center[] --- # Effects on calls to helpline .center[] [Association of 7 million+ tweets featuring suicide-related content with daily calls to the Suicide Prevention Lifeline and with suicides, United States, 2016–2018. Niederkrotenthaler et al (2022)](https://journals.sagepub.com/doi/abs/10.1177/00048674221126649) --- # Effects on suicide statistics .center[] [Association of 7 million+ tweets featuring suicide-related content with daily calls to the Suicide Prevention Lifeline and with suicides, United States, 2016–2018. Niederkrotenthaler et al (2022)](https://journals.sagepub.com/doi/abs/10.1177/00048674221126649) --- # Emotion identification in social media text ## 1. The semantic differential ## 2. Word embeddings ## 3. Language models for social media ## 4. Emotion identification in social media text --- ## State-of-the-practice Sentiment Analysis Pipeline .left-column[  ] .right-column[ 1. Create representative sample of documents from application case 2. Crowdsource annotations (e.g. Mechanical Turk, FigureEight, students...) 3. Split development/training/test samples from annotated documents 4. Develop model using the development sample, evaluate on training sample with cross-validation 5. Train final model on full train sample 6. One evaluation run over test sample. Report performance versus a benchmark including other models and methods 7. Apply model over rest of documents ] --- # Challenges in Emotion Identification <img src="figures/communication.png" width="950" style="display: block; margin: auto;" /> Current sentiment analysis approaches assume that the **ground truth** is an annotation of emotions by **a reader**, often a student or a crowdsourcing worker Noise in ground truth creates **unmeasured error** and potential biases --- ## Vent: Self-annotated Social Media Emotions  <div style="font-size:18pt"><span>Lykousas, N., Patsakis, C., Kaltenbrunner, A., & Gómez. Sharing emotions at scale: The vent dataset. ICWSM (2019)</span></div> --- ### LEIA: Linguistic Embeddings for the Identification of Affect  --- # Emotion-aware masking in pre-training  --- # Vent Datasets Summary </br> | Label | Train | Development | User Test | Time Test | Random Test | |--------------|:------------------:|:----------------:|:----------------:|:----------------:|:----------------:| | Sadness | 1,712,985 | 199,890 | 262,999 | 293,993 | 264,906 | | Anger | 1,517,282 | 147,778 | 224,997 | 205,598 | 226,068 | | Fear | 1,341,624 | 138,929 | 198,264 | 185,461 | 201,563 | | Affection | 979,019 | 144,175 | 161,018 | 191,022| 158,017 | | Happiness | 795,363 | 74,369 | 118,290 | 91,127 | 116,647 | | **Total** | **6,346,273** | **705,141** | **965,568** | **967,201** |** 967,201 ** | --- # Out-Of-Domain Datasets - We gathered datasets of emotion annotations from previous research - We use only test samples to allow future benchmarks - enISEAR and UniversalJoy are reader-annotated. TEC similarly with \#-tags - Affection not present in OOD datasets - Not a hard test of generalizability but a way to explore other domains | Dataset | Source | Year | Sadness | Anger | Fear | Happiness | Total | |---------------|---------|---------|:---------:|:-------:|:------:|:-----------:|:--------------:| | **enISEAR** | Writing tasks | 2019 | 143 | 143 | 143 | 143 | 572 | | **TEC** | Twitter #emo | 2012 | 765 | 305 | 499 | 1,627 | 3,196 | | GoEmotions | Reddit | 2020 | 259 | 520 | 77 | 1,598 | 2,454 | | **Universal Joy** | Facebook | 2021 | 128 | 58 | 11 | 384 | 581 | | SemEval | Twitter | 2018 | 312 | 511 | 165 | 706 | 1,694 | --- # Results in Vent <center>  </center> LEIA outperforms supervised and unsupervised methods for all emotions and test datsets. `\(F_1\)` values between 70 and 80. --- # Out-of-domain results | | LIWC | NRC | NBSVM | LEIA-base | LEIA-large | |---------------|:--------------------:|:--------------------:|:--------------------:|:--------------------:|:--------------------:| | Universal Joy | 23.45 | 28.98 | 41.70 | **54.18** | 54.17 | | GoEmotions | 45.81 | 32.68 | 48.23 | **46.31** | 45.75 | | TEC | 36.02 | 33.92 | 39.07 | 43.87 | **44.12** | | SemEval | 66.72 | 49.86 | 68.77 | **71.68** | 70.04 | | enISEAR | 23.51 | 42.72 | 55.33 | 70.37 | **79.94** | - LEIA is best or tied with the best in all out-of-domain tests - LEIA is best or tied with the best in all emotions except Fear in TEC - Note: very different media, sampling methods, and labelling schemes --- # Comparing with GPT models | | LEIA-base | LEIA-large | GPT-3.5 | GPT-4 | |-----------|--------------------|--------------------|--------------------|--------------------| | Affection | 74.48 | **75.67** | 41.38 | 37.43 | | Anger | 72.92 | **72.98** | 61.79 | 66.82 | | Fear | 69.01 | **70.26** | 51.55 | 60.86 | | Happiness | **77.69** | 77.58 | 67.69 | 68.70 | | Sadness | 67.28 | **68.00** | 59.94 | 64.00 | | Average | 72.28 | **72.90** | 56.47 | 59.56 | - Evaluation on a sample of 1000 texts per emotion label from the user test sample. GPT models used with a standard prompt for zero-shot classification - LEIA greatly outperforms GPT-3.5-turbo and GPT-4 in each emotion --- # Comparing with GPT models (OOD) | | LEIA-base | LEIA-large | GPT-3.5 | GPT-4 | |---------------|--------------------|--------------------|--------------------|--------------------| | Universal Joy | 54.18 | 54.17 | 52.89 | **56.43** | | GoEmotions | 46.31 | 45.75 | **59.06** | 56.45 | | TEC | 43.87 | 44.12 | 52.66 | **54.82** | | SemEval | 71.68 | 70.04 | 80.13 | **81.72** | | enISEAR | 70.37 | 79.94 | 84.96 | **89.97** | - GPT models outperform LEIA in GoEmotions, TEC, SemEval, and enISEAR - LEIA en par with GPT for Universal Joy - Model contamination? test samples for all these datasets are public and GPT models could have been trained with them - Universal Joy might be younger than the cutoff date --- # LEIA (versus) Humans .center[] - Students annotating a balanced Vent sample (N=100, 720 annotations) - Initial results suggest that LEIA is comparable to humans - **Artificial Affective Intelligence:** Can LEIA help humans read emotions? --- # Error analysis with LIME .center[] <a href="https://epjdatascience.springeropen.com/articles/10.1140/epjds/s13688-023-00427-0"> LEIA: Linguistic Embeddings for the Identification of Affect. S. Aroyehun, L. Malik, H. Metzler, N. Haimerl, A. Di Natale, D. Garcia. EPJ Data Science (2023)</a> --- # Summary - **Beginnings of the measurement of meaning** - Dimensionality reduction in average ratings of associations - Not only for words, also for images, fonts, anything with meaning - **Document as context: Latent Semantic Analysis** - Problem of sparseness, highly computationally demanding - **Near words as context: Word embeddings** - A solution to word counting: Distributed Dictionary Representations (DDR) - **The next level: Transformers** - Wide applications: toxicity, suicide-related content, sentiment - Example for emotions in social media text