class: center, middle, inverse, title-slide .title[ # LEIA: Linguistic Embeddings for the Identification of Affect ] .author[ ### David Garcia <br><br> <em>ETH Zurich</em> ] .date[ ### Social Data Science ] --- layout: true <div class="my-footer"><span>David Garcia - Social Data Science - ETH Zurich </span></div> --- ## State-of-the-practice Sentiment Analysis Pipeline .left-column[ 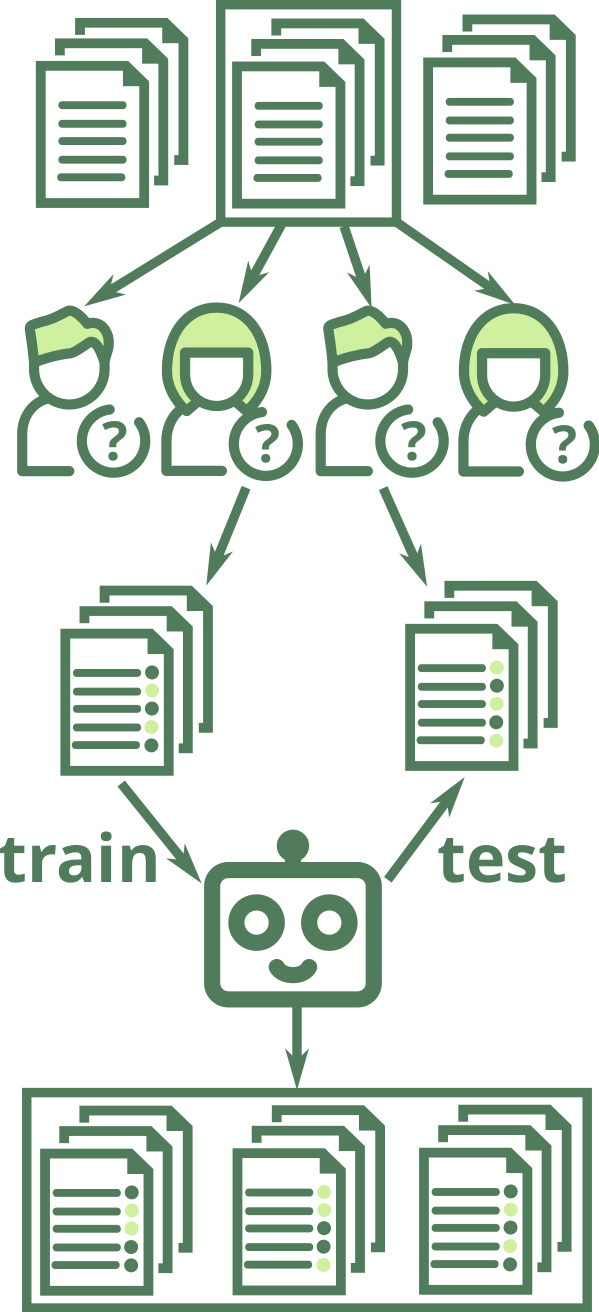 ] .right-column[ 1. Create representative sample of documents from application case 2. Crowdsource annotations (e.g. Mechanical Turk, FigureEight, students...) 3. Split development/training/test samples from annotated documents 4. Develop model using the development sample, evaluate on training sample with cross-validation 5. Train final model on full train sample 6. One evaluation run over test sample. Report performance versus a benchmark including other models and methods 7. Apply model over rest of documents ] --- # Challenges in Emotion Identification <img src="figures/communication.png" width="950" style="display: block; margin: auto;" /> Current sentiment analysis approaches assume that the **ground truth** is an annotation of emotions by **a reader**, often a student or a crowdsourcing worker Noise in ground truth creates **unmeasured error** and potential biases --- ## Vent: Self-annotated Social Media Emotions  <div style="font-size:18pt"><span>Lykousas, N., Patsakis, C., Kaltenbrunner, A., & Gómez. Sharing emotions at scale: The vent dataset. ICWSM (2019)</span></div> --- ### LEIA: Linguistic Embeddings for the Identification of Affect  --- # Vent Datasets Summary </br> | Label | Train | Development | User Test | Time Test | Random Test | |--------------|:------------------:|:----------------:|:----------------:|:----------------:|:----------------:| | Sadness | 1,712,985 | 199,890 | 262,999 | 293,993 | 264,906 | | Anger | 1,517,282 | 147,778 | 224,997 | 205,598 | 226,068 | | Fear | 1,341,624 | 138,929 | 198,264 | 185,461 | 201,563 | | Affection | 979,019 | 144,175 | 161,018 | 191,022| 158,017 | | Happiness | 795,363 | 74,369 | 118,290 | 91,127 | 116,647 | | **Total** | **6,346,273** | **705,141** | **965,568** | **967,201** |** 967,201 ** | --- # Out-Of-Domain Datasets - We gathered datasets of emotion annotations from previous research - We use only test samples to allow future benchmarks - enISEAR and UniversalJoy are reader-annotated. TEC similarly with \#-tags - Affection not present in OOD datasets - Not a hard test of generalizability but a way to explore other domains | Dataset | Source | Year | Sadness | Anger | Fear | Happiness | Total | |---------------|---------|---------|:---------:|:-------:|:------:|:-----------:|:--------------:| | **enISEAR** | Writing tasks | 2019 | 143 | 143 | 143 | 143 | 572 | | **TEC** | Twitter #emo | 2012 | 765 | 305 | 499 | 1,627 | 3,196 | | GoEmotions | Reddit | 2020 | 259 | 520 | 77 | 1,598 | 2,454 | | **Universal Joy** | Facebook | 2021 | 128 | 58 | 11 | 384 | 581 | | SemEval | Twitter | 2018 | 312 | 511 | 165 | 706 | 1,694 | --- # Results in Vent <center>  </center> LEIA outperforms supervised and unsupervised methods for all emotions and test datsets. `\(F_1\)` values between 70 and 80. --- # Out-of-domain results | | LIWC | NRC | NBSVM | LEIA-base | LEIA-large | |---------------|:--------------------:|:--------------------:|:--------------------:|:--------------------:|:--------------------:| | Universal Joy | 23.45 | 28.98 | 41.70 | **54.18** | 54.17 | | GoEmotions | 45.81 | 32.68 | 48.23 | **46.31** | 45.75 | | TEC | 36.02 | 33.92 | 39.07 | 43.87 | **44.12** | | SemEval | 66.72 | 49.86 | 68.77 | **71.68** | 70.04 | | enISEAR | 23.51 | 42.72 | 55.33 | 70.37 | **79.94** | - LEIA is best or tied with the best in all out-of-domain tests - LEIA is best or tied with the best in all emotions except Fear in TEC - Note: very different media, sampling methods, and labelling schemes --- # Comparing with GPT models | | LEIA-base | LEIA-large | GPT-3.5 | GPT-4 | |-----------|--------------------|--------------------|--------------------|--------------------| | Affection | 74.48 | **75.67** | 41.38 | 37.43 | | Anger | 72.92 | **72.98** | 61.79 | 66.82 | | Fear | 69.01 | **70.26** | 51.55 | 60.86 | | Happiness | **77.69** | 77.58 | 67.69 | 68.70 | | Sadness | 67.28 | **68.00** | 59.94 | 64.00 | | Average | 72.28 | **72.90** | 56.47 | 59.56 | - Evaluation on a sample of 1000 texts per emotion label from the user test sample. GPT models used with a standard prompt for zero-shot classification - LEIA greatly outperforms GPT-3.5-turbo and GPT-4 in each emotion --- # Comparing with GPT models (OOD) | | LEIA-base | LEIA-large | GPT-3.5 | GPT-4 | |---------------|--------------------|--------------------|--------------------|--------------------| | Universal Joy | 54.18 | 54.17 | 52.89 | **56.43** | | GoEmotions | 46.31 | 45.75 | **59.06** | 56.45 | | TEC | 43.87 | 44.12 | 52.66 | **54.82** | | SemEval | 71.68 | 70.04 | 80.13 | **81.72** | | enISEAR | 70.37 | 79.94 | 84.96 | **89.97** | - GPT models outperform LEIA in GoEmotions, TEC, SemEval, and enISEAR - LEIA en par with GPT for Universal Joy - Model contamination? test samples for all these datasets are public and GPT models could have been trained with them - Universal Joy might be younger than the cutoff date --- # LEIA (versus) Humans .center[] - Students annotating a balanced Vent sample (N=100, 720 annotations) - Initial results suggest that LEIA is comparable to humans - **Artificial Affective Intelligence:** Can LEIA help humans read emotions? --- # Error analysis with LIME .center[] Try it yourself: https://huggingface.co/saroyehun/LEIA-large --- # For More Information .center[] <a href="https://epjdatascience.springeropen.com/articles/10.1140/epjds/s13688-023-00427-0"> LEIA: Linguistic Embeddings for the Identification of Affect. S. Aroyehun, L. Malik, H. Metzler, N. Haimerl, A. Di Natale, D. Garcia. EPJ Data Science (2023)</a>